Today’s story is about build vs. buy, how I chose wrong and what I learned from this failure about this choice in the age of LLMs.
I’m was brought into a team that’s building a voice bot, with the task of building their observability. When building a bot, it’s vital that we be able to see interactions to audit them, tag them and close the feedback loop to improve quality.
When evaluating the options I was faced with several constraints – This system will contain production data – it has to be secure. It has to integrate into our current user role management. It’s not just read-only observability – users will annotate the inputs. It has to support a streaming architecture, not just http calls.
For reasons of simplicity, we decided not to build or own solution from scratch – that would require bringing in another team with knowledge of building our backoffice frontend apps. I was also very concerned about the TCO of such a system – it’s not just the initial development, we would have to fix bugs, deal with security and performance and incrementally add more capabilities and it would have to be coordinated with this other team.
I decided that it would be better to pay the upfront cost of integrating an existing platform instead. We looked for a self-hosted open source solution and settled on Langfuse which the team had already evaluated in the past as a potential LLM management platform.
The implementation turned out to be anything but smooth. Everything from forcing Langfuse to align with event stream architecture, to the GRC & security hoops we needed to jump through, to what turned out to be a hyper-sensitive configuration of all of the DBs under the hood (Langfuse requires Postgres, Redis and most painfully, Clickhouse) using Terraform that deploys to K8S.
My breaking point turned out to be a full working day where I tried to harden the system by closing a non-secure port and forcing the system to use the secure one. I kept reaching chicken & egg situations where the only way to fix a broken configuration was to reach a non-broken state at which point I would be able to fix the broken state (makes sense right? 🤦🏻♂️). All this for a platform that was not a 100% natural fit for our use case, but just a good-enough solution for the time budget that we had.
I raised a red flag (hopefully early enough) to management and had to admit that we were off-track and barking up the wrong tree.
In parallel, another team member had prototyped an internal page with the exact requirements that we needed – viewing a transcript and even being able to listen in on the conversation and visually asses pauses in speech. Yes, it’s a dreaded “vibe coded” page, but it works!
We decided to use this initial prototype internally within the team. At this point we had just completed the rollout of Cursor to all devs at Next and when we discussed the cost of expanding this prototype to be integrated into our existing backoffice platform, I was surprised to hear that the effort estimate for this was lower than I expected. We ended up planning a roadmap starting with using the page as an internal tool with a gradual port to the backoffice app (that already has user authorization and authentication). Given Cursor, we will probably be able to maintain this app with much less commitment from the backoffice team to support this in the future.
To paraphrase, I was given a choice between the building my own system and integrating a solution. I chose integration and I also had to build 🙂
In retrospect, the main error in my assessment was the cost / benefit of building my own solution – This cost has been dramatically reduced with Cursor (or other LLM tools) and will shift my evaluations going forward. Yes, integrations have also come down in cost with LLMs being able to do a lot of configuration dirty work, but I think that building stuff has come down in cost much more.
I also suspect that companies with dev tools offerings will start facing headwinds as LLM tools gain more traction and teams gain the confidence to dare to build end to end internal solutions instead of “throwing money at the problem”.
Part of building a healthy codebase from day one, is making sure that you have good test coverage. In fact, you might become a victim of your own success, which is what happened to us: Early on, we built such a friendly and streamlined integration testing framework, that our engineers used it extensively, way more than we should have. We wrote tests at the scope of either unit tests or ITs. This had two effects on the system:
Quality was excellent! – Practically anything deployed to production had full test coverage and very few bugs.
Productivity was coming to a halt – Our friendly IT testing framework was causing everyone to write tests that took too long to run, required most services to be up and running, and caused your laptop to glow in the dark.
Keep in mind that we were an early-stage startup; we didn’t have a dedicated Devops team to handle Devex. At this point in time, developers were still responsible for doing Devops work.
To solve this issue, we quickly realized that we had to cut the habit of constantly adding new ITs, and move to component testing – tests that only required a single service to be up for the test to execute.
We needed to migrate to component tests instead of our IT testing framework. But in the meantime, dev machines where still wheezing from running all those services locally, and we couldn’t delay new services from coming online, just because we hadn’t yet made the move to component tests.
Let’s try something
We needed to buy some time. Was it possible to reduce the footprint required for running ITs on dev machines?
Each JVM-based service required a few hundred megabytes of memory. Multiply that by 15 and you see the issue. We quickly ran out of memory on our machines.
What if we could “squish” the services into a single process? This is the experiment I tried out.
Technical background
Let’s get a few technical details out of the way first:
Our services were based on Dropwizard, which is a group of technologies that work well together. As far as the web server, it’s an embedded Jetty server. Each service is an instance of class Service which inherits io.dropwizard.Application and has a main() function that calls a run() command.
The solution
What if we could bundle all of these run() commands into a single main() function? Would they run well together?
Turns out, that multiple Jetty servers can work well within a single JVM process! All we had to do was a bit of deduplication of ports and resources:
We had to make sure that each service listened to a different port
Resources, such as upgrade scripts that sat in the same subdirectory in all services had to move to a uniquely named subdirectory
The code ended up looking something like this:
class UberService {
private val allServices by lazy {
mapOf(
"foo" to FooService(),
"bar" to BarService(),
...
)
}
fun startAllServices(servicesToStart: List<String>) {
// Loop on the services that we want to start and launch each of them in a separate thread
}
}
fun main(args: Array<String>) {
// Get list of services that we want to start from args
include = .... args .....
UberServer().startAllServices(include)
}
Nothing too complex going on here! Since many of the services rarely needed to work in scale on a developer machine, this single process worked well with a memory footprint of much less than 1GB.
This idea ended up buying us about 3 years of breathing room. While these days we have other, better designed solutions for testing our code such as private Kubernetes namespaces for developers, you can still run UberService on your local machine with an input list of dozens of services and it will work nicely.
So, getting back to Elon’s tweet, maybe there is a way to tell your boss that you eliminated 80% of your microservices 🙂
TL;DR – This post shows you how to create a script that checks for available upgrades to third party dependencies in a Gradle libs.versions.toml file
Managing dependencies – What’s missing?
Keeping dependencies up to date is part of ongoing technical debt. It’s not the most glamorous task, but neglect it and you will find yourself in trouble sooner or later.
That’s why it’s important to make it as easy for the organization to “do the right thing” and keep those dependencies up to date with the least friction possible. A great tool for this is Dependabot, which automatically creates PRs with suggested upgrades. We use it a lot. Unfortunately, Dependabot has a limitation – currently, it does not support upgrading *.toml files. We won’t know that it’s time to upgrade libraries listed in the file!
What’s a toml file?
toml is a file format for storing configurations. It’s equivalent to a json, yaml or ini file, and is easily and clearly parseable. A full description of it’s capabilities can be found in the toml project page.
Toml & Gradle
In Gradle, we can define a libs.versions.toml file and use it as a version catalog that is shared between projects. This is great for aligning the versions of third party dependencies and making sure all projects work with the same third party versions. This prevents all sort of nasty bugs that we would get when depending on different versions of the same dependency that we really don’t want to run into.
Let’s take a look at a sample libs.versions.toml file:
As you can see, it’s fairly straightforward and very readable: The versions section defines the version number, while the libraries section defines all our dependencies and uses the version.ref property to refer to the version, enabling us to define the same version for multiple dependencies that belong in the same “family”.
We now need to add a reference to the libs.versions.toml file in our Gradle build. We do that in the settings.gradle.kts file:
OK, so back to our problem: We can’t use Dependabot to generate PRs for updating the libs.versions.toml file. So what can we do that’s the best next thing?
Reviewing the file for available updates is a grueling task. The project that I work on has over 100 different versions in the toml file. Reviewing them one by one and checking each one for the latest version in https://mvnrepository.com/ is not scalable. Our dependencies will probably fall into neglect if we use this approach.
If we had a script that parses the toml file and compares the current version to the latest available version, we’d have a tool that shows us the latest version that’s available. Moreover, if we commit this file, we would be able to see what’s changed since the last commit, next time we run it.
After searching for such a script and and not finding one, I decided to write one myself.
What are the steps that we need the script to perform?
Extract a list of all the third parties.
Look up the current version for each of these third parties.
Look up the latest release for each of them.
Compare the current version to the latest version and output the diff to a file.
With a few exceptions, all of the third parties are hosted in https://repo1.maven.org/maven2/ where each one has a maven-metadata.xml which contains a tag called <release> which holds the latest GA version. That’s our data source for the latest version.
Initially I started out trying to implement this script using bash. After re-learning bash for the n-th time (always fun…), this was the result (feel free to skip to details here):
This script works, but… As one of my reviewers pointed out in the code review (Thanks Shay!) this is hardly maintainable. Good luck debugging this or just understanding what is does.
Now that the proof of concept was, well… proven, I rewrote this in friendlier language: Kotlin script. For those of you not familiar with Kotlin script, it’s just plain Kotlin with some added annotations to help compile the script. You can run it from the command line without any prior compilation.
Here’s the same code, but in readable Kotlin script:
#!/usr/bin/env kotlin
@file:Repository("https://repo1.maven.org/maven2/")
@file:DependsOn("org.tomlj:tomlj:1.1.0")
@file:DependsOn("org.apache.httpcomponents.core5:httpcore5:5.1.4")
import org.apache.hc.core5.http.HttpHost
import org.apache.hc.core5.http.impl.bootstrap.HttpRequester
import org.apache.hc.core5.http.impl.bootstrap.RequesterBootstrap
import org.apache.hc.core5.http.io.entity.EntityUtils
import org.apache.hc.core5.http.io.support.ClassicRequestBuilder
import org.apache.hc.core5.http.protocol.HttpCoreContext
import org.apache.hc.core5.util.Timeout
import org.tomlj.Toml
import org.xml.sax.InputSource
import java.io.FileReader
import java.io.StringReader
import java.net.URI
import javax.xml.parsers.DocumentBuilderFactory
import javax.xml.xpath.XPathConstants
import javax.xml.xpath.XPathExpression
import javax.xml.xpath.XPathFactory
val coreContext: HttpCoreContext = HttpCoreContext.create()
val httpRequester: HttpRequester = RequesterBootstrap.bootstrap().create()
val timeout: Timeout = Timeout.ofSeconds(5)
val mavenTarget: HttpHost = HttpHost.create(URI("https://repo1.maven.org"))
val dbf: DocumentBuilderFactory = DocumentBuilderFactory.newInstance()
val xpathFactory: XPathFactory = XPathFactory.newInstance()
val releasePath = xpathFactory.newXPath().compile("//metadata//versioning//release")!!
main()
fun main() {
val toml = FileReader("./libs.versions.toml").use { file ->
Toml.parse(file)
}
val versions = toml.getTable("versions")!!.toMap()
val libraries = toml.getTable("libraries")!!
val (currentVersionRefs, missingVersions) = libraries.keySet().associate {
val module = libraries.getString("$it.module")!!
val versionRef = libraries.getString("$it.version.ref")
module to versionRef
}.entries.partition { it.value != null }
val currentVersions = currentVersionRefs.associate { it.key to versions.getValue(it.value) }
val latestVersions = currentVersions.mapValues { (packageName, _) ->
getLatestVersion(packageName, mavenTarget, httpRequester, timeout, coreContext, dbf, releasePath)
}
// Compare current to latest version and print if different
currentVersions.toSortedMap().forEach { (packageName, currentVersion) ->
val latestVersion = latestVersions.getValue(packageName)
if (currentVersion != latestVersion) {
println("$packageName: $currentVersion -> $latestVersion")
}
}
if (missingVersions.isNotEmpty()) {
println("\n--- Missing version.ref - Need to check manually ---\n")
println(missingVersions.map { it.key }.sortedBy { it }.joinToString("\n"))
}
}
fun getLatestVersion(packageName: String, mavenTarget: HttpHost?, httpRequester: HttpRequester, timeout: Timeout?, coreContext: HttpCoreContext?, dbf: DocumentBuilderFactory, releasePath: XPathExpression): String {
val (groupId, artifactId) = packageName.split(":")
val path = "${groupId.replace(".", "/")}/$artifactId"
val request = ClassicRequestBuilder.get()
.setHttpHost(mavenTarget).setPath("/maven2/$path/maven-metadata.xml").build()
val xmlString = httpRequester.execute(mavenTarget, request, timeout, coreContext).use { response ->
if (response.code != 200) return "Could not find value in Maven Central. Need to check manually."
EntityUtils.toString(response.entity)
}
val db = dbf.newDocumentBuilder()
val document = db.parse(InputSource(StringReader(xmlString)))
return releasePath.evaluate(document, XPathConstants.STRING).toString()
}
There are a few cases in the toml’s libraries section where we still manage dependencies via the dependencyManagement section of the build.gradle.kts file and the library’s entry does not have a version.ref property. These are not handled by the script and appear in a separate “Missing version.ref” section.
There are a few libraries that are not hosted in Maven Central’s repo but rather in Jitpack’s repo – These are also not handled and a “Could not find value in Maven Central” message is printed instead.
We can see immediately that our AWS lib’s version is not up to date. After committing latest_available_upgrades.txt, next time we run this script, we will also know when AWS publishes a new version of the libraries.
Summary
As you can see, this script automates the chore of checking for third party updates and reduces it to running a single command. It doesn’t create a PR as Dependabot does, but for most cases, it gets us most of the way towards quickly identifying which dependencies require an upgrade.
In this post I’d like to review a case where the use of the very common @JsonProperty annotation leads to unintended coupling.
Let’s take a flight reservation system as our domain example. Each passenger can select his meal preference. We represent this preference with an enum:
enum class MealPreference {
NONE,
VEGETARIAN,
VEGAN,
LACTO_OVO,
KOSHER,
INDIAN
}
This enum is part of the Passenger record:
data class Passenger(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: MealPreference
)
Our app would like to let the passenger edit his profile and change his meal preference. There are some considerations we need to take into account:
The list of preferences could change – we want to maintain the list in a central place so that we don’t need to update separate frontend and backend code. The app can query the backend for a list of valid drop-down values.
We would obviously like to show human readable text in our app, not uppercase constants with underscores
One really simple approach is to add the @JsonProperty annotation:
This looks like a great solution! When we request the passenger information, we’ll get the human readable value. We will also be safe from enum renames breaking the frontend code. The frontend can request allValues and get the full human readable list for displaying in drop-downs, etc.
On second glance, there’s an implicit assumption here: We are equating the @JsonProperty with the display name of the value!
Unfortunately, later on, another business process decided to save the Passenger record to the database. Incidentally, the selected method for saving the data was to save it as a single document, so the Passenger record was serialized into json and saved. As part of this serialization, our enum was serialized into its @JsonProperty value.
Congratulations! We now have a hardwired link between the data saved in the DB and the data displayed in the app.
We can still rename the enum, but on the day we will decide to localize the text, we’re going to find out that we can’t just do it. We now have to first run a project of migrating the DB value into something stable and decoupling it from the app’s displayed value.
What would have been a better approach?
Instead of overloading the use of @JsonProperty, we could have defined a dedicated field for the display name:
The app has a dedicated field, and it can get a list of values via displayValues.
When saving to the DB, we save the enum value. That’s still not ideal, since a rename in the enum might break the DB data, so let’s decouple that too by adding a dbValue field:
When serializing the Passenger record, we need to make sure that the dbValue is used. To that purpose, we define an internal class that will represent the DB record:
data class Passenger(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: MealPreference
) {
companion object {
fun fromDbRecord(dbRecord: DbRecord) = dbRecord.toPassenger()
}
fun toDbRecord() = DbRecord(firstName, lastName, emailAddress, mealPreference.dbValue)
data class DbRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: String
) {
fun toPassenger() = Passenger(firstName, lastName, emailAddress, MealPreference.fromDbValue(mealPreference))
}
}
We now have complete decoupling between the app representation, the business logic code and the DB record representation.
On the downside, there is more boilerplate here – we’re defining a copy of the Passenger class that is only used as a simple DB record, but in my opinion the savings in future development time and reduced decoupling make up for this downside.
As an additional side-benefit, the Passenger class is now free to change structure if we need to do so, without breaking the DB record. For example, Passenger could change to this in the future, with no need to run a DB migration:
data class Passenger(
val person: Person,
val mealPreference: MealPreference
) {
companion object {
fun fromDbRecord(dbRecord: DbRecord) = dbRecord.toPassenger()
}
fun toDbRecord() = DbRecord(person.firstName, person.lastName, person.emailAddress, mealPreference.dbValue)
data class DbRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: String
) {
fun toPassenger() = Passenger(
Person(firstName, lastName, emailAddress),
MealPreference.fromDbValue(mealPreference)
)
}
}
Notice that DbRecord remains unchanged. No DB migration is necessary!
This Sunday, we at Next Insurance kick off our 7th Engineeringfest™, so I thought it might be a good opportunity to talk about what it is and why it’s a really cool thing to also do in your software organization.
So first off, what’s an Engineeringfest? Well, it’s the term we coined for a week or two where the engineering organization focuses on itself. Tomorrow’s round will be held over two weeks.
What do we focus on? Technical debt (A.K.A. the technical backlog).
During these two weeks, we will work on delivering tasks that benefit engineering and, by extension, the whole company.
Once upon a time
Engineeringfest is the result of a bottom up initiative that started 2 years ago.
Next Insurance is a startup that has grown at breakneck speeds in the past few years in all dimensions – headcount, product features and sales to name a few. This is super exciting but obviously also stressful. Part of the stress comes from having to make hard choices between delivery and “correctness” of the system. You sometimes have to choose a faster time to deliver at the expense of doing things the optimal way.
That is OK, as long as it’s a conscious choice that you and your managers are aware of, because, most likely, somewhere along the line, you will have to go back and put in the time to make up for these choices.
Back in late 2018 we reached such a point. We had grown and the strain on the system was showing. Changes to the system were getting harder and harder to make. There were lots of “todos” scattered across the code reminding us of the things we meant to do vs. the things we ended up doing.
We decided to use the upcoming Christmas holiday in the U.S. to work on paying back some of our technical debt. Mind you, our engineering is base mostly outside the U.S. with no Christmas to celebrate, so we figured we would use the last 2 weeks of the year for this effort while non-engineering people in the U.S. office were busy decorating trees and wearing strange sweaters (or whatever people do based on Christmas movies).
Pretty much all of the engineers wanted to be in on this initiative, so we decided to make it an engineering-wide effort. The result was extremely successful. We made a significant impact on our systems. Things that we would not have been able to do during routine feature development. It helped us maintain velocity during 2019 and with buy-in from management and the enthusiasm from the engineers, Engineeringfest became part of Next’s culture.
The goal
There’s a very concrete goal to Engineeringfest: Do what needs to be done in order improve engineering and serve the goal of moving faster. The main themes for these improvements are usually:
Improvements to quality which lead to less development churn and downtime.
Improvements to our workflow process (not just code!).
Work on the build & testing pipeline
Code refactoring that will make it easier to change the system in the future
When an engineer proposes a task to work on, it is evaluated in this context. For example, looking at the planned tickets for this fest here’s a very partial list of things we are going to do, in no particular order (the full list is over 100 tasks long!):
Break down a large table that has become a “repository for everything” into smaller, better defined tables.
Improve the process of handling build failures so that we get back to a green build faster.
Unify a succession of complex API calls into one call.
Spin off some services from a service that has become too large.
Create a simple self-serve data comparison tool for the product managers so that they no longer have to consult engineers to get information.
Create new custom linting rules for catching antipatterns in our code.
Add a new abstraction layer to a part of our data. This will limit the blast radius of future changes to that data.
Break down a dependencies choke point that’s slowing our build.
Add audit data for various entities for easier future debugging.
How does it work?
We have 4 weeks of Engineeringfest every year. They take place for 1 week at the end of Q1 and Q2 and for 2 weeks at the end of Q4.
Since it’s a bottom up event, the engineers get to take their wish list out of their drawers (or pull up their spreadsheets) for things they would like to work on in the fest. Just like any dev effort, there’s a process of planning and demonstrating the value of the tasks you would like to work on, but the requirements and creativity come from within the engineering org, not from the outside.
Why does it work?
Having a dedicated period of self-work gives us many benefits:
Efficiency and workflow
The rest of Next Insurance knows that engineering is not expected to work on other things during this time. Unless it’s an emergency, we will get back to you after the fest. This reduces our context switching.
Even if you happen to be THE go-to person for your system or domain, you will probably not be interrupted by other engineers that need to meet their product delivery deadline. They are also busy working on their own fest task.
We cancel all the routine meetings – dailies, weeklies. This is the only time where even the sacred 1-1 meeting with your manager is skipped. Anything to help people get into the zone of “deep work”.
People and culture
There are many types of engineers. Some live for the internal technical stuff and some really like to deliver features. For the technically oriented engineers, this is the time where they get to really focus on their favorite kind of work. For the delivery engineers, it’s a chance to do something different and touch areas of the system that they would not normally handle.
The fest is as inclusive as it gets! Everyone gets to work on tech debt. Tasks will vary in scope, complexity and level of supervision (if required), but even if you are a graduate just 3 months out of college, you still get to work on a fest task. This works against engineering cultures where refactoring is seen as the responsibility of only seniors and tech leads and helps to instil the habit of looking at the code proactively and continuously thinking about what can be improved.
Planning
A fest task is no different than any other task. When planning we try to maximize the chance of success. If the fest is 10 working days, the task should take as most 7-8 days of work leaving a small buffer. We also break a task of this size down into smaller deliveries. We try to select tasks that are suited for individual work. This maximizes the chances of successful delivery.
Although each team decides on its scope of work, we also coordinate between teams to prevent collisions or overlapping efforts. If another group in the organization such as Devops or BI need to be aware of changes we are going to make, we notify them ahead of the fest to make sure they are able to support the effort if needed.
The result is a super-effective week (or two).
What is it not?
Given this effort, it’s also important to realize that there are some things that Engineeringfest is not:
Engineeringfest is not a substitute for routine gardening and housekeeping of your systems. If you only work on your technical backlog during the fest, you are doing it wrong!
Whenever we see some unexpected non-delivery work that needs to be done, it’s very tempting to just throw it into the Engineeringfest bucket and say “I’ll deal with it then”. You might find yourself reaching the fest with a huge list you can never hope to handle. Don’t let it be the excuse to not handle issues!
Not all types of work are suitable for Engineeringfest.
Some work needs to take place over months. Engineeringfest might be a good point to kick off, but it’s not going to be enough.
Some work requires many dependencies between teams and people and is not suited to independent work.
Some work requires time between iterations to see how it affects the system. Engineeringfest is too short for this type of work.
The purpose of Engineeringfest is to improve velocity. The goal is not to try out new stuff for the sake of innovation or for playing with new technologies, unless they contribute to the goal of velocity. In fact, adding new technology oftentimes adds complexity and overhead which is the exact opposite of our goal! So think hard and well before adding new and strange cogs to the machine.
This also leads us to the risk of misaligned expectations: Engineeringfest is not a hackathon, and there is a risk that if you do not communicate this clearly, people will want to use the time for unrelated experiments or projects, which have their place, but not as part of the fest.
Business not as usual
As part of making Engineeringfest feel non-routine, we’ve also developed traditions around the process:
Normally, we work with Jira for tickets. In Engineeringfest we still do that but there’s also a visual element to the work: Each developer takes an A4 sized sheet of paper for each feature they will work on. The feature is written down with the occasional illustration (as can be seen in this post’s banner). We hang them on a “todo” wall, decorating the office. Each time something is done, the paper is moved to the “done” wall accompanied by the ring of a cowbell or gong. The sense of team accomplishment and individual recognition is much more pronounced compared to a status change in Jira 🙂
This year with COVID, the gong will be replaced by a dedicated Slack channel.
For many of the engineers, this Engineeringfest will be the first, and the fest has a strong social component that helps them to get to know people outside their immediate circle of contacts. We always set a round or two of social games, whether it’s board game evening or a things-you-didn’t-know-about quiz. This year, obviously, it will all be held online, with social games over Zoom.
Conclusion
While it’s generally agreed that every engineering org should devote at least 20% of its time to the technical backlog (and oftentimes more than that), come crunch time, these tasks are usually the first to go out the window. The result is an organization with an unbalanced ratio between delivery and housekeeping. The fest helps keep the ratio in balance.
I think the reason that I like Engineeringfest so much is that it’s not only about the work that’s done. It’s a reflection of a kind of engineering culture that I aspire to be part of.
Internally within engineering, it’s about pride in our work, caring about how our systems are designed and coded, not just about the raw outcome and delivery. It encourages everyone in the organization to come up with ideas for improvement and allows them time to implement them.
The fest itself is not only about raw metrics and velocity. It’s a statement that the agenda that’s important to engineering is also important to the company as a whole and that success of this agenda contributes to the success of the company.
There are many ways to iterate over collections in Kotlin. Assuming you also want to collect results as you iterate, you can run the gamut with syntax styles ranging from the very Java-esque to super streamlined functional code.
Naive iteration on a collection
Let’s take an example of a loop that receives a list of customer IDs and sends them an email. Our boilerplate will look like this:
class Iterations {
private val customerIds = List(100) {
Integer.toHexString(Random.nextInt(256 * 256))
}
private fun sendEmail(customerId: String): Boolean {
println("Sending email to customer $customerId")
sleep(500)
return Random.nextInt(2) == 0
}
}
We have a list of 100 customer ID strings and a function that calls our email provider. The function takes 500ms to complete and returns a boolean success indicator.
Our first pass at creating the send loop is a style that you might see with Java developers making the transition to Kotlin, with little experience in functional programming.
Create a list of responses, iterate with a for loop and add the response to the result list. Return the statuses.
fun sendEmails1(): List<Boolean> {
val statuses = mutableListOf<Boolean>()
for (customerId in customerIds) {
val response = sendEmail(customerId)
statuses.add(response)
}
return statuses
}
This is, of course, very verbose, and also makes unnecessary use of a mutable list. We can improve on this quite easily:
fun sendEmails2(): List<Boolean> {
val statuses = mutableListOf<Boolean>()
customerIds.forEach { customerId ->
val response = sendEmail(customerId)
statuses.add(response)
}
return statuses
}
We’re still using a mutable list, but using a forEach on the collection. Not much of an improvement. Let’s keep going:
fun sendEmails3(): List<Boolean> {
val statuses = customerIds.map { customerId ->
val response = sendEmail(customerId)
response
}
return statuses
}
We’ve made the jump from forEach to map which saves us the trouble of allocating a list of results. Now to clean up and streamline the code:
fun sendEmails4() = customerIds.map { customerId -> sendEmail(customerId) }
The function is inlined. The response variable has been removed. We’ve even removed the explicit return type for brevity. From 6 lines of code we are down to 1.
As a side-note, implicit return types and putting everything in one line are not necessarily Best Practice. I recommend watching Putting Down the Golden Hammer from KotlinConf 2019 for an interesting discussion on that. This is just an example taken to the absolute extreme for the sake of discussion.
As far as performance, all implementations will take ~50 seconds to run (100 x 500ms).
A wrench in the gears
Now comes the twist: We have to be able to stop mid-way. We are shutting down our process and we need to interrupt our run.
Let’s expand our boilerplate to include a shutdown flag:
class Iterations {
private val customerIds = List(100) {
Integer.toHexString(Random.nextInt(256 * 256))
}
private val shouldShutDown = AtomicBoolean(false)
private fun isShuttingDown(): AtomicBoolean {
sleep(200)
return shouldShutDown
}
init {
Thread {
sleep(3000)
shouldShutDown.set(true)
}.start()
}
private fun sendEmail(customerId: String): Boolean {
println("Sending email to customer $customerId")
sleep(500)
return Random.nextInt(2) == 0
}
This shutdown flag comes with a cost – 200ms of performance. In the example, the flag is in-memory, but it could also be a call to the DB or an external API. The list of customers could be 100K items long, not 100. Therefore we are simulating a time penalty for the flag check. We also initialize a background thread that will raise the shutdown flag after 3 seconds. Total time for each iteration will be 700ms (500 for sending the email + 200 for checking the flag)
How can we add the check to our code?
Let’s try and make a minimal change:
fun sendWithInterrupt1(): List<Boolean> = customerIds.mapNotNull { customerId ->
if (isShuttingDown().get()) return@mapNotNull null
sendEmail(customerId)
}
We’re still using map. Sort of. We just modified it to mapNotNull. We’ve made the minimal change, and the code is still relatively clean and readable. But mapNotNull will evaluate the entire collection. After 3 seconds, we have processed 5 customers (3000ms / 700ms rounded up). We will pass through 95 more redundant iterations that will cost us about 19 seconds to pass through – 95 calls x 200ms to check the flag. This is unacceptable. We should stop immediately.
The solution that’s staring us in the face is to abandon our map and go back to using forEach:
fun sendWithInterrupt2(): List<Boolean> {
val statuses = mutableListOf<Boolean>()
customerIds.forEach { customerId ->
if (isShuttingDown().get()) return statuses
val response = sendEmail(customerId)
statuses.add(response)
}
return statuses
}
This is ugly. We have a return in two places. We’re back to a mutable list. But we will stop after 3.5 seconds. We have traded readability and elegance in return for performance.
Is there a way to eat our cake and have it too (or is it having your cake and eating it too)? Anyway, we want to stick to a functional style, but also be able to stop mid-evaluation. Turns out that there is a way to do this in Kotlin: Sequences.
Quick reminder here: Kotlin collections are eagerly evaluated by default. Sequences are lazily evaluated.
We added asSequence before map. The flag check is in the takeWhile section. This acts as our stop criteries – a While condition. We wrap it up with toList().
Now, the only terminal operation here is the toList. All other operations return an intermediate sequence that is not immediately evaluated. When we run this, total running time is about 3.5 seconds – the time it takes to process 5 email sends and flag checks.
What’s the right way to go? (A.K.A. Tradeoffs)
Looking at this final version, I can’t say wholeheartedly that it is the ideal solution. Yes, the style is very functional and looks like a pipeline, but on the other hand, another developer looking at this code may not be familiar with these lesser knows operators (takeWhile, asSequence). We are adding a slight learning curve.
We did manage to avoid mutable lists and intermediate variables, keeping the code tight and leaving less room for future modifications that might lead us down a dark path.
The code is definitely more Kotlin-y and more idiomatic, but some might argue that the KISS principle should guide us to stick with the mutable, non-functional version.
Overall, my personal preference would be to go with this last version, but my recommendation to the engineer who was responsible for the change was to make the call himself according to his preference. There are more important hills to die on ¯\_(ツ)_/¯
This article discusses the shutdown of background tasks during a rolling deployment.
The backstory
Early on, when our team was still small, we would occasionally run into the following error in production:
java.lang.IllegalStateException: ServiceLocatorImpl(__HK2_Generated_0,0,1879131528) has been shut down
at org.jvnet.hk2.internal.ServiceLocatorImpl.checkState(ServiceLocatorImpl.java:2288)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandleImpl(ServiceLocatorImpl.java:629)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandle(ServiceLocatorImpl.java:622)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandle(ServiceLocatorImpl.java:640)
at org.jvnet.hk2.internal.FactoryCreator.getFactoryHandle(FactoryCreator.java:103)
... 59 common frames omitted
Wrapped by: org.glassfish.hk2.api.MultiException: A MultiException has 1 exceptions. They are:
We quickly realized that this error was due to a long-running job that was in the middle of its run during deployment. A service would shut down, the DI framework would kill various components and the job would end up trying to use a decomissioned instance of a class.
Since the team was still small and everyone in the (single) room was aware of the deployment, solving this was put on the back burner – a known issue that was under our control. We had bigger fish to free *.
Eventually, the combination of team size growth and the move to continuous deployment meant that we could no longer afford to ignore this error. An engineer on shift who is no longer familiar with the entire system cannot be relied on to “just know” that this is an “acceptable” error (I would add several more quotes around “acceptable” if I could). The deploys also reached a pace of dozens every day, so we were much more likely to run into the error.
Let’s dive into some more detail about the issue we faced.
The graceful shutdown problem
During deployment, incoming external connections are handled by our infrastructure. Connections are drained using the load balancer to route connections and wait for existing connections to close.
Scheduled tasks are not triggered externally and are not handled by the infrastructure. They require a custom applicative solution in order to shut down gracefully.
The setting
The task we’re talking about is a background task, triggered by Quartz and running in Dropwizard with an infrastructure of AWS Elastic Beanstalk (EBS) that manages deployments. Our backend code is written in Kotlin, but is simple enough to understand even if you are not familiar with the language.
Rolling deployments
Rolling (ramped) deploys are a deployment method where we gradually take a group of servers that run a service offline, deploy a new version, wait for the server to come back online and move on to the next server.
This method allows us to maintain high availability while deploying a new version across our servers.
In AWS’ Elastic Beanstalk (EBS), you can configure a service to perform a rolling deploy on the EC2 instances that run a service. The load balancer will stop routing traffic to an EC2 instance and wait for open connections to close. After all connections have closed (or when we reach a max timeout period), the instance will be restarted.
The load balancer does not have any knowledge of what’s going on with our service beyond the open connections and whether the service is responding to health checks.
Shutting down our background tasks
Let’s divide what needs to be done into the following steps:
Prevent new background jobs from launching.
Signal long running jobs and let them know that we are about to shut down.
Wait for all jobs to complete, up to a maximum waiting period.
Getting the components to talk to each other
The first challenge that we come across is triggering the shutdown sequence. EBS is not aware of the EC2 internals, and certainly not of Quartz jobs running in the JVM. All it does, unless we intervene, is send an immediate shutdown signal.
We need to create a link between EBS and Quartz, to let Quartz know that it needs to shut down. This needs to be done ahead of time, not at the point at which we destroy the instance.
Fortunately, we can use Dropwizard’s admin capabilities for this purpose. Dropwizard enables us to define tasks that are mounted via the admin path by inheriting the abstract class Task. Let’s look at what it does:
class ShutdownTask(private val scheduler: Scheduler) : Task("shutdown") {
override fun execute(parameters: Map<String, List<String>>, output: PrintWriter) {
// Stop triggering new jobs before shutdown
scheduler.standby()
// Wait until all jobs are done up to a maximum of time
// This is in order to prevent immediate shutdown that may occur if there are no open connections to the server
val startTime = System.currentTimeMillis()
while (scheduler.currentlyExecutingJobs.size > 0 && System.currentTimeMillis() - startTime < MAX_WAIT_MS) {
sleep(1000)
}
}
}
Some notes about the code:
The task receives a reference to the Quartz scheduler in its constructor. This allows it to call the standby method in order to stop the launch of new jobs
We call standby, not shutdown, so that jobs that are running will be able to complete their run and save their state in the Quartz tables. shutdown would close the connection to those tables.
We wait up to MAX_WAIT_MS before continuing. If there are no running jobs, we continue immediately.
EBS does not have a minimum time window during which it stops traffic to the instance. If there are no open connections to the process, EBS will trigger a shutdown immediately. This is why we need to check for running jobs and wait for them, not just call the standby method and move on.
Given a reference to Dropwizard’s environment on startup, we can call
to initialize the task. Once added to the environment, we can trigger the task via a POST call to
http://<server>:<adminport>/tasks/shutdown
The last thing we need to do is add this call to EBS’ deployment. EBS provides hooks for the deploy lifecycle – pre, enact and post. In our case we will add it to the pre stage. In the .ebextensions directory, we’ll add the following definition in a 00-shutdown.config file:
files:
"/opt/elasticbeanstalk/hooks/appdeploy/pre/00_shutdown.sh":
mode: "000755"
owner: root
group: root
content: |
#! /bin/bash
echo "Stopping Quartz jobs"
curl -s -S -X POST http://<server>:<adminport>/tasks/shutdown
echo "Quartz shutdown completed, moving on with deployment."
So far we have accomplished steps #1 & #3 – Preventing new jobs from launching and waiting for running jobs to complete. However, if there are long running jobs that take more than MAX_WAIT_MS to complete, we will reach the time out and they will still terminate unexpectedly.
Signaling to running jobs
We put a timeout of MAX_WAIT_MS to protect our deployment from hanging due to a job that is not about to terminate (we could also put a -max-time on the curl command).
Many long running jobs are batch jobs that process a collection of items. In this step, we would also like to give them a chance to terminate in a controlled fashion – Give them a chance to record their state, notify other components of their termination or perform other necessary cleanups.
Let’s give these jobs this ability.
We’ll start with a standard Quartz job that has no knowledge the state of the system:
class SomeJob: Job {
override fun execute(context: JobExecutionContext) {
repeat(1000) { runner ->
println("Iteration $runner - Doing something that takes time")
sleep(1000)
}
}
}
We want to be able to stop the job. Let’s define an interface that will let us do that:
interface StoppableJob {
fun stopJob()
}
Now, let’s implement the interface:
class SomeStoppableJob: Job, StoppableJob {
@Volatile
private var isActive: Boolean = true
override fun execute(context: JobExecutionContext) {
repeat(1000) { runner ->
if (!isActive) {
println("Job has been stopped, stopping on iteration $runner")
return
}
println("Iteration $runner - Doing something that takes time")
sleep(1000)
}
}
override fun stopJob() {
isActive = false
}
}
This setup allows us to pause execution. Notice that our flag needs to be volatile. Now we can modify ShutdownTask to halt the execution of all running tasks:
class ShutdownTask(private val scheduler: Scheduler) : Task("shutdown") {
override fun execute(parameters: Map<String, List<String>>, output: PrintWriter) {
// Stop triggering new jobs before shutdown
scheduler.standby()
scheduler.currentlyExecutingJobs
.map { it.jobInstance }
.filterIsInstance(StoppableJob::class.java)
.forEach {
it.stopJob()
}
// Wait until all jobs are done up to a maximum of time
// This is in order to prevent immediate shutdown that may occur if there are no open connections to the server
val startTime = System.currentTimeMillis()
while (scheduler.currentlyExecutingJobs.size > 0 && System.currentTimeMillis() - startTime < MAX_WAIT_MS) {
sleep(1000)
}
}
}
Conclusion
Looking at the implementation, we now have the ability to control long-running tasks and have them complete without incident.
It reduces noise in production that would otherwise send engineers scrambling to see whether there is a real problem, or just a deployment artefact. This enabled us to focus on real issues and improve the quality of our shifts.
Detekt is a static code analyzer for Kotlin. This post talks about how I used Detekt for non-trivial, systematic improvements to code quality, using custom Detekt rules.
I review a lot of pull requests on a regular basis. During reviews, antipatterns show up all the time. Many of them are repetitive and addressing them is important, but does not involve deep insight into the code. In fact, repetitive nitpicking in code reviews is an antipattern in itself. Repeating the same points over and over is exasperating, and they keep popping up in PRs coming from different developers.
Sometimes you see an antipattern that is so bad that it sends you on a gardening task to weed out all instances of it in the codebase. One such example is the instantiation of Jackson’s ObjectMapper.
Antipattern example – misusing ObjectMapper
Instantiating an ObjectMapper is intensive as far as object allocation and memory use. If you’re not careful and causally use it in code that is called frequently, it will cause memory churn – the intensive allocation and release of objects, leading to frequent garbage collection. This can directly contribute to the instability of a JVM process.
Let’s have a look at an example of bad usage of the ObjectMapper: We have a CustomerRecord class which represents a DB record. This record has a json string field. When we fetch the record we want to convert the record into a DTO. This requires us to deserialize the string so that we can access the serialized object.
data class CustomerRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val preferences: String // json
) {
fun toDto(): CustomerDto {
val preferences = ObjectMapper().registerModule(KotlinModule()).readValue<CustomerPreferences>(preferences)
return CustomerDto(
firstName,
lastName,
emailAddress,
preferences.language,
preferences.currency
)
}
}
The problem here is that with each invocation of toDto(), we are creating a new instance of ObjectMapper.
How bad is it? Let’s create a test and compare performance. For comparison, version #2 of this code has a statically instantiated ObjectMapper:
data class CustomerRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val preferences: String // json
) {
companion object {
private val objectMapper = ObjectMapper()
.registerModule(KotlinModule()) // To enable no default constructor
}
fun toDtoStatic(): CustomerDto {
val preferences = objectMapper.readValue<CustomerPreferences>(preferences)
return CustomerDto(
firstName,
lastName,
emailAddress,
preferences.language,
preferences.currency
)
}
}
Let’s compare performance:
Iterations
New Duration (Deserializations / s)
Static Duration (Deserializations / s)
Ratio
10K
767ms (13,037)
44ms (227,272)
x17
100K
4675ms (21,390)
310ms (322,580)
x15
1M
37739ms (26,504)
1556ms (642,673)
x24
New – creating ObjectMapper() in each iteration Static – creating ObjectMapper() once
This is an amazing result! Extracting the ObjectMapper to a static field and preventing an instance from being created each time has improved performance by a factor of over 20 in some cases. This is the ratio of time that initializing an ObjectMapper takes vs. what the actual derserialization takes.
The problem with the one-time gardener
A large codebase could have hundreds of cases of bad ObjectMapper usages. Even worse, a month after cleaning up the codebase and getting rid of all these cases, some new engineers will join the group. They are not familiar with the best practice of static ObjectMappers and inadvertently reintroduce this antipattern into the code.
The solution here is to proactively prevent engineers from committing such code. It should not be up to me, the reviewer to catch such errors. After all, I should be focusing on deeper insights into the code, not on being a human linter.
Detekt to our aid
To catch these antipatterns in Kotlin, I used a framework called Detekt. Detekt is a static code analyzer for Kotlin. It provides many code smell rules out of the box. A lesser known feature is that it can be extended with custom rules.
Let’s first try and figure out what would valid uses of ObjectMapper look like. An ObjectMapper would be valid if instantiated:
Statically, in a companion class
In a top level object which is a singleton itself
In a private variable in the top-level of a file, outside of a class but not accessible from outside the file
What would an ObjectMapper code smell look like? When it’s instantiated:
As a member of a class that may be instantiated many times
As a member of an object that is not a companion object within a class (highly unlikely but still…)
I created a rule to detect the bad usages and permit the good ones. In order to do this, I extended Detekt’s Rule abstract class.
Detekt uses the visitor pattern, exposing a semantic tree of the code via dozens of functions that can be overridden in Rule. Each function is invoked for a different component in the code. At first glance, it’s hard to understand which is the correct method to override. It took quite a bit of trial and error to figure out that the correct function to override is visitCallExpression. This function is invoked for all expressions in the code, including the instantiation of ObjectMapper.
An example of how we examine the expression can be found in class JsonMapperAntipatternRule. We search the expression’s parents for the first class & object instances. Depending on what we find, we examine the expression in the context of a class or of a file.
val objectIndex = expression.parents.indexOfFirst { it is KtObjectDeclaration }
val classIndex = expression.parents.indexOfFirst { it is KtClass }
val inFileScope = objectIndex == -1 && classIndex == -1
if (inFileScope) {
validateFileScope(expression)
} else {
validateObjectScope(objectIndex, classIndex, expression)
}
Test coverage can be found in JsonMapperAntipatternRuleTest. Tests include positive and negative examples and can be added as we encounter more edge cases that we may not have thought of.
The positive test cases we want to allow:
// Private ObjectMapper in class' companion object
class TestedUnit {
companion object {
private val objectMapper = ObjectMapper()
}
}
// ObjectMapper in object
object TestedObject {
private val objectMapper = ObjectMapper()
}
// Private ObjectMapper in file (top level)
private val objectMapper = ObjectMapper()
class TestedObject {
}
// Part of a more complex expression
private val someObject = ObjectMapper().readValue("{}")
class TestedObject {
}
On the other hand, cases which we want to prevent:
// ObjectMapper not in companion class
class TestedUnit {
private val objectMapper = ObjectMapper()
}
// Within a non-companion object
class External {
object Internal {
val notGood = ObjectMapper()
}
}
// Not private in top level of file
val notGood = ObjectMapper()
class External {
}
The detekt-custom-rules module is a minimal Detekt plugin module. Once built, the result is a jar that can be used interactively within IntelliJ, or as a plugin when building the rest of the project.
Using the plugin with IntelliJ
After installing the Detekt plugin in IntelliJ, we enable it and point it to the plugin jar like so:
The result is that we now have syntax highlighting for this issue:
Using the plugin with a Maven build
To use is as part of the build, we need to point the maven plugin to the jar:
With the plugin in place we receive a warning during the build:
custom-rules - 5min debt
JsonMapperAntipatternRule - [preferences] at detekt-antipatterns/customers/src/main/java/com/ygaller/detekt/CustomerRecord.kt:18:23
In detekt.yml it’s possible to configure the build to either fail or just warn on the custom rule.
Conclusion
Using Detekt and the custom rule, I managed to screen for a non-trivial antipattern. Adding it to IntelliJ and to the build means that it is much less likely to pop up in future code reviews.
Moreover, it decenteralizes the knowledge of this issue and enables any engineer working on our code in the future to be alerted to the fact that he is introducing an inefficiency into the system. One that can easily be avoided.
Let’s talk about different options for separating services and domains, in the context of synchronous vs. event driven architectures.
Many times, we find ourselves with a need for a change in architecture. There are several alternatives with various tradeoffs between them. We are going to review one such case today.
Acmetrade – The direct trading company
Our story is about Acmetrade, a company providing a direct stock trading platform for individual investors.
At Acmitrade, an individual investor can create an account, transfer funds and start trading right away. It’s easy, simple and customers love it.
The platform that Acmetrade provides is so good that a while back, investment managers (IMs) started requesting to manage their customers’ portfolios on the platform. Management identified this opportunity for increased revenue and decided to create an Investment Manager offering based on the original platform. This new product has been an unqualified success, driving significant revenue.
Acmetrade’s R&D
Within the R&D organization, the accounts domain is maintained by the Accounts team. Its mandate is anything related to managing the account’s lifecycle – account creation, deposits, withdrawals, etc. The accounts team is responsible for the Accounts microservice.
To support the investment management domain, a new team was formed – the IM (Investment Management) team. Its purpose is to develop the investment management offering. The main service which they maintain is the IM microservice. It manages all the data and exposes all the functions that are needed for working with investment managers.
Acmetrade’s Architecture
Acmetrade provides customers and investment managers with a web portal.
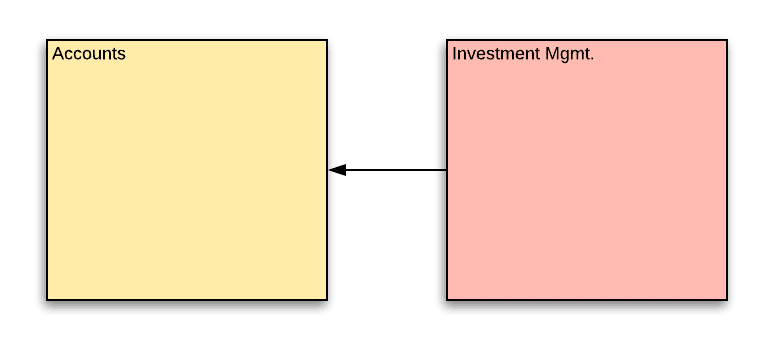
Since the accounts domain and the IM domain are mostly accessed by these portals, the team provides a REST HTTP api for the webapps to call. The communication model is synchronous HTTP API calls.
The core domain that should not depend on any other is accounts. It should not be aware of whether it is managed by an investment manager. The IM domain does have a dependency on the accounts domain and holds references to account entities that are under IM management.
What’s the problem?
When the IM functionality was introduced, it was clear that the accounts team would have to incorporate IM functionality into various account business flows. The IM team went about making modifications to the account service, under supervision of the accounts team – the owners of the accounts domain.
While this was a trickle and harmless at first, the rapid growth of IM functionality now means that anything that is done in the accounts team must also factor the effect on the IM domain.
It’s a classic case of feature creep. Any new feature, in this case investment managers, must be supported from now on in each and every flow. But that’s ok, right? The domains are separate and there are different teams addressing the different concerns. Well, turns out things have gotten out of hand lately and the boundaries between the domains have become blurred. Code that is the responsibility of the IM team is located in the accounts service. For good reason – there’s temporal coupling between actions in the account and IM actions.
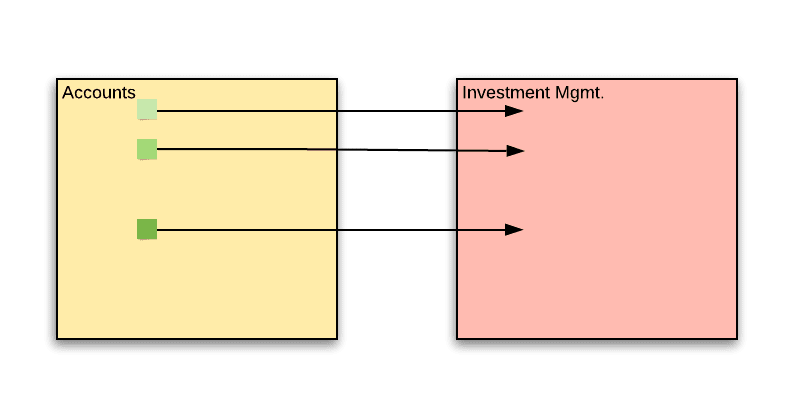
Some examples of IM -> accounts dependencies are obvious:
There’s a need to calculate investment managers’ commissions based on activity of accounts under management
The IM portal provides a summary of accounts under management
The problem is that over time, some backward dependencies have formed. These are cases where accounts started “being aware” of the existence of investment managers:
When an account is created, the accounts service lets the IM service know that the new account should be affiliated with an IM.
When the customer deposits funds, the investment manager is notified of the deposit via email. The account service queries the IM service for the managing investment manager and adds him as a CC recipient to the confirmation email that is sent to the customer.
The AccountData DTO used by the UI contains a section with information about the assigned IM. This data is requested from the IM service.
The accounts domain has been “infected” with IM data, and we need to take action in order to prevent the domains from becoming entangled even further.
Why do we care? Well, if they become fully entangled, it will be impossible for the teams to work independently. Responsibility for the code will cease to be well defined. The IM team will be knee deep in accounts code and vice versa. This has already started to affect development velocity as well as code quality. The accounts team now need to understand the IM domain in addition to their domain. This is distracting them and making reasoning about the system much more difficult.
The ideal solution
Given unlimited time and engineers, the right way to go about solving this would be to eliminate the account service’s dependency on the IM service. IM work within the account service should move to where it really belongs – the IM service.
What’s the best way to eliminate the dependencies? Let’s look at the cases:
For cases #1 and #2 in the previous section, moving to an event architecture would make sense. The account service would publish an “account created” event and a “funds deposited” event. The IM service would listen to these events and act accordingly. This is great! The account service no longer needs to be aware of the existence of the IM service. It just has to declare that an event has taken place.
As for #3, we are abusing the account service by also serving as a “portal gateway” service for composing the DTO that is returned to the portal. The solution here would be to create a portal gateway service that would be in charge of the composition of the response to the frontend. It would depend on the accounts service and on the IM service. The accounts service would no longer depend on the IM service.
Why is the ideal not ideal?
There is, however, a major problem. When asked to give an effort estimate for the work involved, the teams gave a “large” t-shirt size estimate for the work. At least 2 weeks, maybe more. Right now, the targets for the quarter are already set and doing this would derail other important work. Given that this is not an immediate fire that needs to be put out, work can start next quarter at the earliest. In addition, there are various drawbacks to changing the architecture:
Pubsub drawbacks
Creating a pubsub infrastructure involves writing a lot of new code. This code will take time to stabilize.
We are adding new components to the system. These components – queues & topics, may break. For the change to go live, the team needs to have monitoring and automated testing in place.
Actions that were atomic are now separate – we need to consider states of inconsistency and how to remedy them in case of failure.
People who are used to working with a synchronous model now need to think with a different, event driven, mindset.
Gateway service drawbacks
Creating a new service means additional complexity in monitoring and deployment.
The gateway service will be the responsibility of a third team – The front-end team which is responsible for such services. More communication overhead!
The Tradeoff
The team realizes that if they go for the ideal solution, it will never reach maturity within a reasonable time span. Meanwhile, the complexity of the system continues to grow, and refactoring becomes even harder.
Are there any short-term low cost alternatives that they can develop as a stop-gap until the team is able to provide a robust solution to the issues?
Alternatives
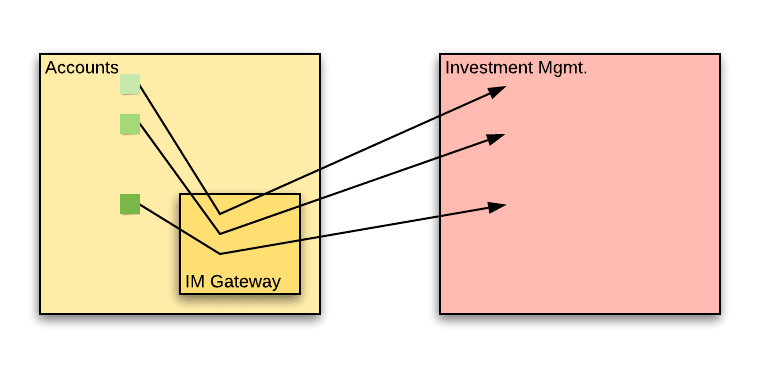
The IM Gateway
To start with, the accounts team could start treating the IM service as a proper third party. Up until now, they teams, which have worked closely, have treated each other’s code as familiar codebases, instead of code that is opaque.
When accessing a third party API, it is good practice to wrap the access to that API with a gateway component. Privately, this component manages calls to the external API. Publicly, the component exposes a set of calls so that the rest of the accounts service only needs to know about the component. Let’s call this the IM Gateway.
Why is this important? What is the benefit here?
It limits the change in the accounts service to within the gateway. Any changes in the IM service will only reflect on a single point – the IM Gateway. The rest of the accounts service is isolated from changes.
It makes it easy to understand the extent of use of the IM API within the accounts service. A simple “find usage” search on the IM Gateway will show all the places in the accounts service that refer to IM logic.
It improves service testability – Once you have a central IM Gateway component, mocking it is much simpler. Mock a single component and all your tests can work with it, instead of having to intercept calls to the IM service all across the codebase.
The team’s effort estimate to create this gateway is only 2 days! They can definitely squeeze it into their schedule.
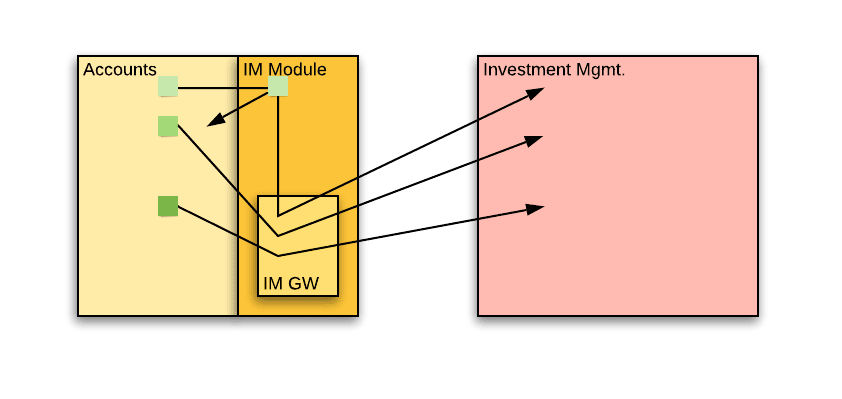
The IM Module
The IM Gateway was a great step forward. But the IM business logic still remains in place and is dispersed throughout the service. The next step in isolating IM dependencies is to concentrate the IM business logic into a single module – contrast this with just passing all calls to the IM service via a gateway as in the previous step.
Once this module is complete, it will be much easier to “pick it up” and move it to the IM service. It is essentially doing all the IM work, except that we are still inside the accounts service. All calls to the module should pass an object, equivalent in structure to the external event that we would publish to the pubsub infrastructure.
The team estimates the work required for this step as one week of work.
The module would provide:
Account linking – The module receives an “event” object. It calls internal endpoints in the accounts service to collect information, just as the IM service would were it to receive such an event. It then calls the IM service in order to link the account to an IM.
Notifications – Up until now, we sent a single email with a “to” recipient (the account owner) and a “cc” recipient (the IM). Moving the logic of sending the IM email into the module would mean sending two separate emails. This means two actions instead of one, which means managing intermediate states and failures.
The Portal Gateway package
To deal with composing the DTO that we return to the frontend portal, the team creates a portal gateway package in the codebase. This isolates the access to IM information for display purposes to a single package. We remove references to the IM module from core account entities where they were present up to now. When we decide to create a proper portal gateway service, all we will need to do is move this package between services.
The effort estimate here is only 1 day.
The end state
The steps the team took have brought us to a much better state:
In total, the change took 2 weeks of immediate work, instead of taking at least a month, starting sometime in the next quarter. Moreover, this work is not throwaway work, but rather an intermediate step to build upon towards the ideal solution.
IM code is now much less pervasive in the accounts service’s codebase
The IM team can now work in a safer environment with almost all of the changes happening in a single area (the module).
The accounts team does not need to supervise work done by the IM team in the accounts service as closely.
The accounts team has less fear of unexpected changes. There’s less communication overhead due to increased decoupling.
Conclusion
The work that the team did puts us in a better position to reach the ideal, event based solution. In fact, if it untangles the code and sets boundaries, it may buy the teams months of breathing room and may ultimately prove to be a sustainable status quo, saving a lot of premature and unnecessary optimization.
While not the perfect solution, it might just be good enough and is a good example of a tradeoff between the unattainable correct solution and real life constraints.