Part of building a healthy codebase from day one, is making sure that you have good test coverage. In fact, you might become a victim of your own success, which is what happened to us: Early on, we built such a friendly and streamlined integration testing framework, that our engineers used it extensively, way more than we should have. We wrote tests at the scope of either unit tests or ITs. This had two effects on the system:
Quality was excellent! – Practically anything deployed to production had full test coverage and very few bugs.
Productivity was coming to a halt – Our friendly IT testing framework was causing everyone to write tests that took too long to run, required most services to be up and running, and caused your laptop to glow in the dark.
Keep in mind that we were an early-stage startup; we didn’t have a dedicated Devops team to handle Devex. At this point in time, developers were still responsible for doing Devops work.
To solve this issue, we quickly realized that we had to cut the habit of constantly adding new ITs, and move to component testing – tests that only required a single service to be up for the test to execute.
We needed to migrate to component tests instead of our IT testing framework. But in the meantime, dev machines where still wheezing from running all those services locally, and we couldn’t delay new services from coming online, just because we hadn’t yet made the move to component tests.
Let’s try something
We needed to buy some time. Was it possible to reduce the footprint required for running ITs on dev machines?
Each JVM-based service required a few hundred megabytes of memory. Multiply that by 15 and you see the issue. We quickly ran out of memory on our machines.
What if we could “squish” the services into a single process? This is the experiment I tried out.
Technical background
Let’s get a few technical details out of the way first:
Our services were based on Dropwizard, which is a group of technologies that work well together. As far as the web server, it’s an embedded Jetty server. Each service is an instance of class Service which inherits io.dropwizard.Application and has a main() function that calls a run() command.
The solution
What if we could bundle all of these run() commands into a single main() function? Would they run well together?
Turns out, that multiple Jetty servers can work well within a single JVM process! All we had to do was a bit of deduplication of ports and resources:
We had to make sure that each service listened to a different port
Resources, such as upgrade scripts that sat in the same subdirectory in all services had to move to a uniquely named subdirectory
The code ended up looking something like this:
class UberService {
private val allServices by lazy {
mapOf(
"foo" to FooService(),
"bar" to BarService(),
...
)
}
fun startAllServices(servicesToStart: List<String>) {
// Loop on the services that we want to start and launch each of them in a separate thread
}
}
fun main(args: Array<String>) {
// Get list of services that we want to start from args
include = .... args .....
UberServer().startAllServices(include)
}
Nothing too complex going on here! Since many of the services rarely needed to work in scale on a developer machine, this single process worked well with a memory footprint of much less than 1GB.
This idea ended up buying us about 3 years of breathing room. While these days we have other, better designed solutions for testing our code such as private Kubernetes namespaces for developers, you can still run UberService on your local machine with an input list of dozens of services and it will work nicely.
So, getting back to Elon’s tweet, maybe there is a way to tell your boss that you eliminated 80% of your microservices 🙂
In this post I’d like to review a case where the use of the very common @JsonProperty annotation leads to unintended coupling.
Let’s take a flight reservation system as our domain example. Each passenger can select his meal preference. We represent this preference with an enum:
enum class MealPreference {
NONE,
VEGETARIAN,
VEGAN,
LACTO_OVO,
KOSHER,
INDIAN
}
This enum is part of the Passenger record:
data class Passenger(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: MealPreference
)
Our app would like to let the passenger edit his profile and change his meal preference. There are some considerations we need to take into account:
The list of preferences could change – we want to maintain the list in a central place so that we don’t need to update separate frontend and backend code. The app can query the backend for a list of valid drop-down values.
We would obviously like to show human readable text in our app, not uppercase constants with underscores
One really simple approach is to add the @JsonProperty annotation:
This looks like a great solution! When we request the passenger information, we’ll get the human readable value. We will also be safe from enum renames breaking the frontend code. The frontend can request allValues and get the full human readable list for displaying in drop-downs, etc.
On second glance, there’s an implicit assumption here: We are equating the @JsonProperty with the display name of the value!
Unfortunately, later on, another business process decided to save the Passenger record to the database. Incidentally, the selected method for saving the data was to save it as a single document, so the Passenger record was serialized into json and saved. As part of this serialization, our enum was serialized into its @JsonProperty value.
Congratulations! We now have a hardwired link between the data saved in the DB and the data displayed in the app.
We can still rename the enum, but on the day we will decide to localize the text, we’re going to find out that we can’t just do it. We now have to first run a project of migrating the DB value into something stable and decoupling it from the app’s displayed value.
What would have been a better approach?
Instead of overloading the use of @JsonProperty, we could have defined a dedicated field for the display name:
The app has a dedicated field, and it can get a list of values via displayValues.
When saving to the DB, we save the enum value. That’s still not ideal, since a rename in the enum might break the DB data, so let’s decouple that too by adding a dbValue field:
When serializing the Passenger record, we need to make sure that the dbValue is used. To that purpose, we define an internal class that will represent the DB record:
data class Passenger(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: MealPreference
) {
companion object {
fun fromDbRecord(dbRecord: DbRecord) = dbRecord.toPassenger()
}
fun toDbRecord() = DbRecord(firstName, lastName, emailAddress, mealPreference.dbValue)
data class DbRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: String
) {
fun toPassenger() = Passenger(firstName, lastName, emailAddress, MealPreference.fromDbValue(mealPreference))
}
}
We now have complete decoupling between the app representation, the business logic code and the DB record representation.
On the downside, there is more boilerplate here – we’re defining a copy of the Passenger class that is only used as a simple DB record, but in my opinion the savings in future development time and reduced decoupling make up for this downside.
As an additional side-benefit, the Passenger class is now free to change structure if we need to do so, without breaking the DB record. For example, Passenger could change to this in the future, with no need to run a DB migration:
data class Passenger(
val person: Person,
val mealPreference: MealPreference
) {
companion object {
fun fromDbRecord(dbRecord: DbRecord) = dbRecord.toPassenger()
}
fun toDbRecord() = DbRecord(person.firstName, person.lastName, person.emailAddress, mealPreference.dbValue)
data class DbRecord(
val firstName: String,
val lastName: String,
val emailAddress: String,
val mealPreference: String
) {
fun toPassenger() = Passenger(
Person(firstName, lastName, emailAddress),
MealPreference.fromDbValue(mealPreference)
)
}
}
Notice that DbRecord remains unchanged. No DB migration is necessary!
This article discusses the shutdown of background tasks during a rolling deployment.
The backstory
Early on, when our team was still small, we would occasionally run into the following error in production:
java.lang.IllegalStateException: ServiceLocatorImpl(__HK2_Generated_0,0,1879131528) has been shut down
at org.jvnet.hk2.internal.ServiceLocatorImpl.checkState(ServiceLocatorImpl.java:2288)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandleImpl(ServiceLocatorImpl.java:629)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandle(ServiceLocatorImpl.java:622)
at org.jvnet.hk2.internal.ServiceLocatorImpl.getServiceHandle(ServiceLocatorImpl.java:640)
at org.jvnet.hk2.internal.FactoryCreator.getFactoryHandle(FactoryCreator.java:103)
... 59 common frames omitted
Wrapped by: org.glassfish.hk2.api.MultiException: A MultiException has 1 exceptions. They are:
We quickly realized that this error was due to a long-running job that was in the middle of its run during deployment. A service would shut down, the DI framework would kill various components and the job would end up trying to use a decomissioned instance of a class.
Since the team was still small and everyone in the (single) room was aware of the deployment, solving this was put on the back burner – a known issue that was under our control. We had bigger fish to free *.
Eventually, the combination of team size growth and the move to continuous deployment meant that we could no longer afford to ignore this error. An engineer on shift who is no longer familiar with the entire system cannot be relied on to “just know” that this is an “acceptable” error (I would add several more quotes around “acceptable” if I could). The deploys also reached a pace of dozens every day, so we were much more likely to run into the error.
Let’s dive into some more detail about the issue we faced.
The graceful shutdown problem
During deployment, incoming external connections are handled by our infrastructure. Connections are drained using the load balancer to route connections and wait for existing connections to close.
Scheduled tasks are not triggered externally and are not handled by the infrastructure. They require a custom applicative solution in order to shut down gracefully.
The setting
The task we’re talking about is a background task, triggered by Quartz and running in Dropwizard with an infrastructure of AWS Elastic Beanstalk (EBS) that manages deployments. Our backend code is written in Kotlin, but is simple enough to understand even if you are not familiar with the language.
Rolling deployments
Rolling (ramped) deploys are a deployment method where we gradually take a group of servers that run a service offline, deploy a new version, wait for the server to come back online and move on to the next server.
This method allows us to maintain high availability while deploying a new version across our servers.
In AWS’ Elastic Beanstalk (EBS), you can configure a service to perform a rolling deploy on the EC2 instances that run a service. The load balancer will stop routing traffic to an EC2 instance and wait for open connections to close. After all connections have closed (or when we reach a max timeout period), the instance will be restarted.
The load balancer does not have any knowledge of what’s going on with our service beyond the open connections and whether the service is responding to health checks.
Shutting down our background tasks
Let’s divide what needs to be done into the following steps:
Prevent new background jobs from launching.
Signal long running jobs and let them know that we are about to shut down.
Wait for all jobs to complete, up to a maximum waiting period.
Getting the components to talk to each other
The first challenge that we come across is triggering the shutdown sequence. EBS is not aware of the EC2 internals, and certainly not of Quartz jobs running in the JVM. All it does, unless we intervene, is send an immediate shutdown signal.
We need to create a link between EBS and Quartz, to let Quartz know that it needs to shut down. This needs to be done ahead of time, not at the point at which we destroy the instance.
Fortunately, we can use Dropwizard’s admin capabilities for this purpose. Dropwizard enables us to define tasks that are mounted via the admin path by inheriting the abstract class Task. Let’s look at what it does:
class ShutdownTask(private val scheduler: Scheduler) : Task("shutdown") {
override fun execute(parameters: Map<String, List<String>>, output: PrintWriter) {
// Stop triggering new jobs before shutdown
scheduler.standby()
// Wait until all jobs are done up to a maximum of time
// This is in order to prevent immediate shutdown that may occur if there are no open connections to the server
val startTime = System.currentTimeMillis()
while (scheduler.currentlyExecutingJobs.size > 0 && System.currentTimeMillis() - startTime < MAX_WAIT_MS) {
sleep(1000)
}
}
}
Some notes about the code:
The task receives a reference to the Quartz scheduler in its constructor. This allows it to call the standby method in order to stop the launch of new jobs
We call standby, not shutdown, so that jobs that are running will be able to complete their run and save their state in the Quartz tables. shutdown would close the connection to those tables.
We wait up to MAX_WAIT_MS before continuing. If there are no running jobs, we continue immediately.
EBS does not have a minimum time window during which it stops traffic to the instance. If there are no open connections to the process, EBS will trigger a shutdown immediately. This is why we need to check for running jobs and wait for them, not just call the standby method and move on.
Given a reference to Dropwizard’s environment on startup, we can call
to initialize the task. Once added to the environment, we can trigger the task via a POST call to
http://<server>:<adminport>/tasks/shutdown
The last thing we need to do is add this call to EBS’ deployment. EBS provides hooks for the deploy lifecycle – pre, enact and post. In our case we will add it to the pre stage. In the .ebextensions directory, we’ll add the following definition in a 00-shutdown.config file:
files:
"/opt/elasticbeanstalk/hooks/appdeploy/pre/00_shutdown.sh":
mode: "000755"
owner: root
group: root
content: |
#! /bin/bash
echo "Stopping Quartz jobs"
curl -s -S -X POST http://<server>:<adminport>/tasks/shutdown
echo "Quartz shutdown completed, moving on with deployment."
So far we have accomplished steps #1 & #3 – Preventing new jobs from launching and waiting for running jobs to complete. However, if there are long running jobs that take more than MAX_WAIT_MS to complete, we will reach the time out and they will still terminate unexpectedly.
Signaling to running jobs
We put a timeout of MAX_WAIT_MS to protect our deployment from hanging due to a job that is not about to terminate (we could also put a -max-time on the curl command).
Many long running jobs are batch jobs that process a collection of items. In this step, we would also like to give them a chance to terminate in a controlled fashion – Give them a chance to record their state, notify other components of their termination or perform other necessary cleanups.
Let’s give these jobs this ability.
We’ll start with a standard Quartz job that has no knowledge the state of the system:
class SomeJob: Job {
override fun execute(context: JobExecutionContext) {
repeat(1000) { runner ->
println("Iteration $runner - Doing something that takes time")
sleep(1000)
}
}
}
We want to be able to stop the job. Let’s define an interface that will let us do that:
interface StoppableJob {
fun stopJob()
}
Now, let’s implement the interface:
class SomeStoppableJob: Job, StoppableJob {
@Volatile
private var isActive: Boolean = true
override fun execute(context: JobExecutionContext) {
repeat(1000) { runner ->
if (!isActive) {
println("Job has been stopped, stopping on iteration $runner")
return
}
println("Iteration $runner - Doing something that takes time")
sleep(1000)
}
}
override fun stopJob() {
isActive = false
}
}
This setup allows us to pause execution. Notice that our flag needs to be volatile. Now we can modify ShutdownTask to halt the execution of all running tasks:
class ShutdownTask(private val scheduler: Scheduler) : Task("shutdown") {
override fun execute(parameters: Map<String, List<String>>, output: PrintWriter) {
// Stop triggering new jobs before shutdown
scheduler.standby()
scheduler.currentlyExecutingJobs
.map { it.jobInstance }
.filterIsInstance(StoppableJob::class.java)
.forEach {
it.stopJob()
}
// Wait until all jobs are done up to a maximum of time
// This is in order to prevent immediate shutdown that may occur if there are no open connections to the server
val startTime = System.currentTimeMillis()
while (scheduler.currentlyExecutingJobs.size > 0 && System.currentTimeMillis() - startTime < MAX_WAIT_MS) {
sleep(1000)
}
}
}
Conclusion
Looking at the implementation, we now have the ability to control long-running tasks and have them complete without incident.
It reduces noise in production that would otherwise send engineers scrambling to see whether there is a real problem, or just a deployment artefact. This enabled us to focus on real issues and improve the quality of our shifts.
Let’s talk about different options for separating services and domains, in the context of synchronous vs. event driven architectures.
Many times, we find ourselves with a need for a change in architecture. There are several alternatives with various tradeoffs between them. We are going to review one such case today.
Acmetrade – The direct trading company
Our story is about Acmetrade, a company providing a direct stock trading platform for individual investors.
At Acmitrade, an individual investor can create an account, transfer funds and start trading right away. It’s easy, simple and customers love it.
The platform that Acmetrade provides is so good that a while back, investment managers (IMs) started requesting to manage their customers’ portfolios on the platform. Management identified this opportunity for increased revenue and decided to create an Investment Manager offering based on the original platform. This new product has been an unqualified success, driving significant revenue.
Acmetrade’s R&D
Within the R&D organization, the accounts domain is maintained by the Accounts team. Its mandate is anything related to managing the account’s lifecycle – account creation, deposits, withdrawals, etc. The accounts team is responsible for the Accounts microservice.
To support the investment management domain, a new team was formed – the IM (Investment Management) team. Its purpose is to develop the investment management offering. The main service which they maintain is the IM microservice. It manages all the data and exposes all the functions that are needed for working with investment managers.
Acmetrade’s Architecture
Acmetrade provides customers and investment managers with a web portal.
Since the accounts domain and the IM domain are mostly accessed by these portals, the team provides a REST HTTP api for the webapps to call. The communication model is synchronous HTTP API calls.
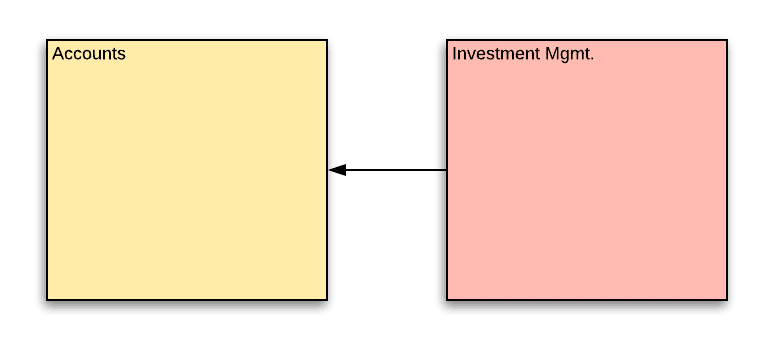
The core domain that should not depend on any other is accounts. It should not be aware of whether it is managed by an investment manager. The IM domain does have a dependency on the accounts domain and holds references to account entities that are under IM management.
What’s the problem?
When the IM functionality was introduced, it was clear that the accounts team would have to incorporate IM functionality into various account business flows. The IM team went about making modifications to the account service, under supervision of the accounts team – the owners of the accounts domain.
While this was a trickle and harmless at first, the rapid growth of IM functionality now means that anything that is done in the accounts team must also factor the effect on the IM domain.
It’s a classic case of feature creep. Any new feature, in this case investment managers, must be supported from now on in each and every flow. But that’s ok, right? The domains are separate and there are different teams addressing the different concerns. Well, turns out things have gotten out of hand lately and the boundaries between the domains have become blurred. Code that is the responsibility of the IM team is located in the accounts service. For good reason – there’s temporal coupling between actions in the account and IM actions.
Some examples of IM -> accounts dependencies are obvious:
There’s a need to calculate investment managers’ commissions based on activity of accounts under management
The IM portal provides a summary of accounts under management
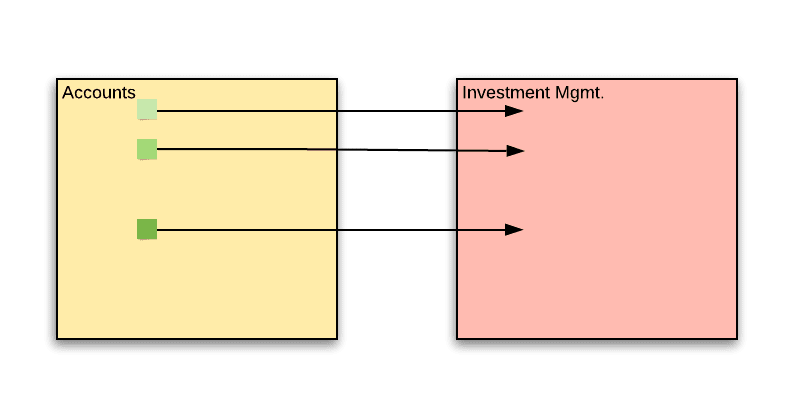
The problem is that over time, some backward dependencies have formed. These are cases where accounts started “being aware” of the existence of investment managers:
When an account is created, the accounts service lets the IM service know that the new account should be affiliated with an IM.
When the customer deposits funds, the investment manager is notified of the deposit via email. The account service queries the IM service for the managing investment manager and adds him as a CC recipient to the confirmation email that is sent to the customer.
The AccountData DTO used by the UI contains a section with information about the assigned IM. This data is requested from the IM service.
The accounts domain has been “infected” with IM data, and we need to take action in order to prevent the domains from becoming entangled even further.
Why do we care? Well, if they become fully entangled, it will be impossible for the teams to work independently. Responsibility for the code will cease to be well defined. The IM team will be knee deep in accounts code and vice versa. This has already started to affect development velocity as well as code quality. The accounts team now need to understand the IM domain in addition to their domain. This is distracting them and making reasoning about the system much more difficult.
The ideal solution
Given unlimited time and engineers, the right way to go about solving this would be to eliminate the account service’s dependency on the IM service. IM work within the account service should move to where it really belongs – the IM service.
What’s the best way to eliminate the dependencies? Let’s look at the cases:
For cases #1 and #2 in the previous section, moving to an event architecture would make sense. The account service would publish an “account created” event and a “funds deposited” event. The IM service would listen to these events and act accordingly. This is great! The account service no longer needs to be aware of the existence of the IM service. It just has to declare that an event has taken place.
As for #3, we are abusing the account service by also serving as a “portal gateway” service for composing the DTO that is returned to the portal. The solution here would be to create a portal gateway service that would be in charge of the composition of the response to the frontend. It would depend on the accounts service and on the IM service. The accounts service would no longer depend on the IM service.
Why is the ideal not ideal?
There is, however, a major problem. When asked to give an effort estimate for the work involved, the teams gave a “large” t-shirt size estimate for the work. At least 2 weeks, maybe more. Right now, the targets for the quarter are already set and doing this would derail other important work. Given that this is not an immediate fire that needs to be put out, work can start next quarter at the earliest. In addition, there are various drawbacks to changing the architecture:
Pubsub drawbacks
Creating a pubsub infrastructure involves writing a lot of new code. This code will take time to stabilize.
We are adding new components to the system. These components – queues & topics, may break. For the change to go live, the team needs to have monitoring and automated testing in place.
Actions that were atomic are now separate – we need to consider states of inconsistency and how to remedy them in case of failure.
People who are used to working with a synchronous model now need to think with a different, event driven, mindset.
Gateway service drawbacks
Creating a new service means additional complexity in monitoring and deployment.
The gateway service will be the responsibility of a third team – The front-end team which is responsible for such services. More communication overhead!
The Tradeoff
The team realizes that if they go for the ideal solution, it will never reach maturity within a reasonable time span. Meanwhile, the complexity of the system continues to grow, and refactoring becomes even harder.
Are there any short-term low cost alternatives that they can develop as a stop-gap until the team is able to provide a robust solution to the issues?
Alternatives
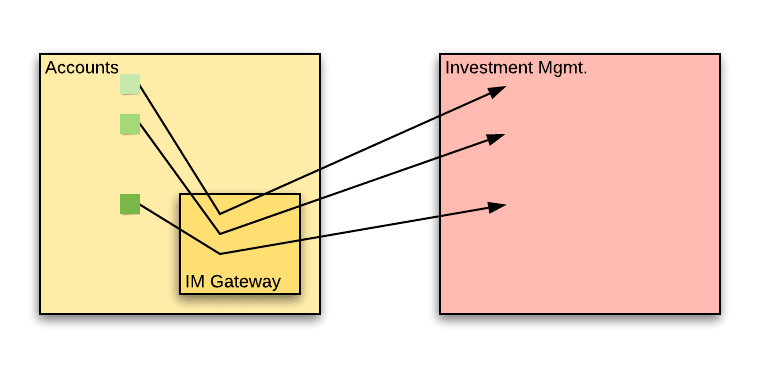
The IM Gateway
To start with, the accounts team could start treating the IM service as a proper third party. Up until now, they teams, which have worked closely, have treated each other’s code as familiar codebases, instead of code that is opaque.
When accessing a third party API, it is good practice to wrap the access to that API with a gateway component. Privately, this component manages calls to the external API. Publicly, the component exposes a set of calls so that the rest of the accounts service only needs to know about the component. Let’s call this the IM Gateway.
Why is this important? What is the benefit here?
It limits the change in the accounts service to within the gateway. Any changes in the IM service will only reflect on a single point – the IM Gateway. The rest of the accounts service is isolated from changes.
It makes it easy to understand the extent of use of the IM API within the accounts service. A simple “find usage” search on the IM Gateway will show all the places in the accounts service that refer to IM logic.
It improves service testability – Once you have a central IM Gateway component, mocking it is much simpler. Mock a single component and all your tests can work with it, instead of having to intercept calls to the IM service all across the codebase.
The team’s effort estimate to create this gateway is only 2 days! They can definitely squeeze it into their schedule.
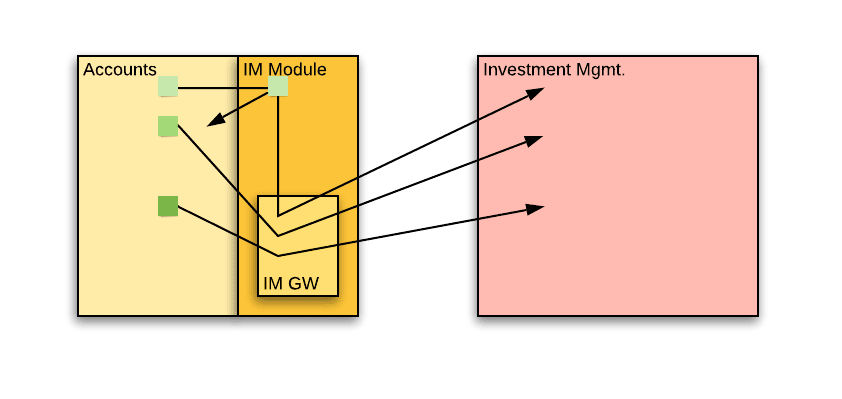
The IM Module
The IM Gateway was a great step forward. But the IM business logic still remains in place and is dispersed throughout the service. The next step in isolating IM dependencies is to concentrate the IM business logic into a single module – contrast this with just passing all calls to the IM service via a gateway as in the previous step.
Once this module is complete, it will be much easier to “pick it up” and move it to the IM service. It is essentially doing all the IM work, except that we are still inside the accounts service. All calls to the module should pass an object, equivalent in structure to the external event that we would publish to the pubsub infrastructure.
The team estimates the work required for this step as one week of work.
The module would provide:
Account linking – The module receives an “event” object. It calls internal endpoints in the accounts service to collect information, just as the IM service would were it to receive such an event. It then calls the IM service in order to link the account to an IM.
Notifications – Up until now, we sent a single email with a “to” recipient (the account owner) and a “cc” recipient (the IM). Moving the logic of sending the IM email into the module would mean sending two separate emails. This means two actions instead of one, which means managing intermediate states and failures.
The Portal Gateway package
To deal with composing the DTO that we return to the frontend portal, the team creates a portal gateway package in the codebase. This isolates the access to IM information for display purposes to a single package. We remove references to the IM module from core account entities where they were present up to now. When we decide to create a proper portal gateway service, all we will need to do is move this package between services.
The effort estimate here is only 1 day.
The end state
The steps the team took have brought us to a much better state:
In total, the change took 2 weeks of immediate work, instead of taking at least a month, starting sometime in the next quarter. Moreover, this work is not throwaway work, but rather an intermediate step to build upon towards the ideal solution.
IM code is now much less pervasive in the accounts service’s codebase
The IM team can now work in a safer environment with almost all of the changes happening in a single area (the module).
The accounts team does not need to supervise work done by the IM team in the accounts service as closely.
The accounts team has less fear of unexpected changes. There’s less communication overhead due to increased decoupling.
Conclusion
The work that the team did puts us in a better position to reach the ideal, event based solution. In fact, if it untangles the code and sets boundaries, it may buy the teams months of breathing room and may ultimately prove to be a sustainable status quo, saving a lot of premature and unnecessary optimization.
While not the perfect solution, it might just be good enough and is a good example of a tradeoff between the unattainable correct solution and real life constraints.